Rejection sampling
In mathematics, rejection sampling is a basic technique used to generate observations from a distribution. It is also commonly called the acceptance-rejection method or "accept-reject algorithm" and is a type of Monte Carlo method. The method works for any distribution in with a density.

Rejection sampling is based on the observation that to sample a random variable one can perform a uniformly random sampling of the 2D cartesian graph, and keep the samples in the region under the graph of its density function.[1][2][3][4] Note that this property can be extended to N-dimension functions.
Description
To visualize the motivation behind rejection sampling, imagine graphing the density function of a random variable onto a large rectangular board and throwing darts at it. Assume that the darts are uniformly distributed around the board. Now remove all of the darts that are outside the area under the curve. The remaining darts will be distributed uniformly within the area under the curve, and the x-positions of these darts will be distributed according to the random variable's density. This is because there is the most room for the darts to land where the curve is highest and thus the probability density is greatest.
The visualization as just described is equivalent to a particular form of rejection sampling where the proposal distribution is uniform (hence its graph is a rectangle). The general form of rejection sampling assumes that the board is not necessarily rectangular but is shaped according to some distribution that we know how to sample from (for example, using inversion sampling), and which is at least as high at every point as the distribution we want to sample from, so that the former completely encloses the latter. Otherwise, there will be parts of the curved area we want to sample from that can never be reached. Rejection sampling works as follows:
- Sample a point on the x-axis from the proposal distribution.
- Draw a vertical line at this x-position, up to the curve of the proposal distribution.
- Sample uniformly along this line from 0 to the maximum of the probability density function. If the sampled value is greater than the value of the desired distribution at this vertical line, return to step 1.
This algorithm can be used to sample from the area under any curve, regardless of whether the function integrates to 1. In fact, scaling a function by a constant has no effect on the sampled x-positions. Thus, the algorithm can be used to sample from a distribution whose normalizing constant is unknown, which is common in computational statistics.
Examples
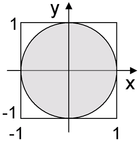
As a simple geometric example, suppose it is desired to generate a random point within the unit circle. Generate a candidate point where and are independent uniformly distributed between −1 and 1. If it so happens that then the point is within the unit circle and should be accepted. If not then this point should be rejected and another candidate should be generated.




The ziggurat algorithm, a more advanced example, is used to efficiently generate normally-distributed pseudorandom numbers.
Theory
The rejection sampling method generates sampling values from a target distribution with arbitrary probability density function by using a proposal distribution with probability density . The idea is that one can generate a sample value from by instead sampling from and accepting the sample from with probability , repeating the draws from until a value is accepted. here is a constant, finite bound on the likelihood ratio , satisfying over the support of ; in other words, M must satisfy for all values of . Note that this requires that the support of must include the support of —in other words, whenever .











The validation of this method is the envelope principle: when simulating the pair , one produces a uniform simulation over the subgraph of . Accepting only pairs such that then produces pairs uniformly distributed over the subgraph of and thus, marginally, a simulation from





This means that, with enough replicates, the algorithm generates a sample from the desired distribution . There are a number of extensions to this algorithm, such as the Metropolis algorithm and the combination with ratio-of-uniforms approach.[5]
This method relates to the general field of Monte Carlo techniques, including Markov chain Monte Carlo algorithms that also use a proxy distribution to achieve simulation from the target distribution . It forms the basis for algorithms such as the Metropolis algorithm.
The unconditional acceptance probability is the proportion of proposed samples which are accepted, which is
![{\displaystyle {\begin{aligned}\mathbb {P} \left(U\leq {\frac {f(x)}{Mg(x)}}\right)&=\operatorname {E} \left[\mathbb {P} \left(U\leq {\frac {f(x)}{Mg(x)}}{\biggr |}x\right)\right]\\&=E\left[{\frac {f(x)}{Mg(x)}}\right]\\&=\int {\frac {f(z)}{Mg(z)}}g(z)dz\\&={\frac {1}{M}}\int f(z)dz\\&={\frac {1}{M}}\end{aligned}}}](../I/m/38ff2e4c2c0999022dd12584a9ae5fdb535ae43d.svg)
where , and the value of each time is generated under the density function of the proposal distribution .

The number of samples required from to obtain an accepted value thus follows a geometric distribution with probability , which has mean . Intuitively, is the expected number of the iterations that are needed, as a measure of the computational complexity of the algorithm.

Rewrite the above equation,

Note that , due to the above formula, where is a probability which can only take values in the interval . When is chosen closer to one, the unconditional acceptance probability is higher the less that ratio varies, since is the upper bound for the likelihood ratio . In practice, a value of closer to 1 is preferred as it implies fewer rejected samples, on average, and thus fewer iterations of the algorithm. In this sense, one prefers to have as small as possible (while still satisfying , which suggests that should generally resemble in some way. Note, however, that cannot be equal to 1: such would imply that , i.e. that the target and proposal distributions are actually the same distribution.


![[0,1]](../I/m/738f7d23bb2d9642bab520020873cccbef49768d.svg)


Rejection sampling is most often used in cases where the form of makes sampling difficult. A single iteration of the rejection algorithm requires sampling from the proposal distribution, drawing from a uniform distribution, and evaluating the expression. Rejection sampling is thus more efficient than some other method whenever M times the cost of these operations—which is the expected cost of obtaining a sample with rejection sampling—is lower than the cost of obtaining a sample using the other method.
Algorithm
The algorithm (used by John von Neumann and dating back to Buffon and his needle) to obtain a sample from distribution with density using samples from distribution with density is as follows:


- Obtain a sample from distribution and a sample from (the uniform distribution over the unit interval).
- Check whether or not .
- If this holds, accept as a sample drawn from ;
- if not, reject the value of and return to the sampling step.



The algorithm will take an average of iterations to obtain a sample.
Advantages over sampling using naive methods
Rejection sampling can be far more efficient compared with the Naive methods in some situations. For example, given a problem as sampling conditionally on given the set , i.e., , sometimes can be easily simulated, using the Naive methods (e.g. by inverse transform sampling):




- Sample independently, and leave those satisfying
- Output:


The problem is this sampling can be difficult and inefficient, if . The expected number of iterations would be , which could be close to infinity. Moreover, even when you apply Rejection sampling method, it is always hard to optimize the bound for the likelihood ratio. More often than not, is large and the rejection rate is high, the algorithm can be very inefficient. The Natural Exponential Family (if it exists), also known as exponential tilting, provides a class of proposal distributions that can lower the computation complexity, the value of and speed up the computations (see examples: working with Natural Exponential Families).


Examples: working with natural exponential families
Given a random variable , is the target distribution. Assume for the simplicity, the density function can be explicitly written as . Choose the proposal as


![{\displaystyle {\begin{aligned}F_{\theta }(x)&=\mathbb {E} \left[\mathrm {exp} (\theta X-\psi (\theta ))\mathbb {I} (X\leq x)\right]\\&=\int _{-\infty }^{x}e^{\theta y-\psi (\theta )}f(y)dy\\g_{\theta }(x)&=F_{\theta }^{'}(x)=e^{\theta x-\psi (\theta )}f(x)\end{aligned}}}](../I/m/ffc16c49b4f83ded4e5cd49d14d059aaed44705d.svg)
where and . Clearly, , is from a natural exponential family. Moreover, the likelihood ratio is




Note that implies that it is indeed a log moment-generation function, that is, . And it is easy to derive the log moment-generation function of the proposal and therefore the proposal's moments.



As a simple example, suppose under , , with . The goal is to sample , . The analysis goes as followed.



![{\displaystyle X|X\in \left[b,\infty \right]}](../I/m/636c3f2bbc375c8db222d2822d2477cfc3029fde.svg)

- Choose the form of the proposal distribution , with log moment-generating function as , which further implies it is a normal distribution .
- Decide the well chosen for the proposal distribution. In this setup, the intuitive way to choose is to set , that is
- Explicitly write out the target, the proposal and the likelihood ratio







- Derive the bound for the likelihood ratio , which is a decreasing function for , therefore

![{\displaystyle x\in [b,\infty ]}](../I/m/49f20788c9a89c22df431d305ef569115f50cb0d.svg)

- Rejection sampling criterion: for , if

holds, accept the value of ; if not, continue sampling new and new until acceptance.


For the above example, as the measurement of the efficiency, the expected number of the iterations the NEF-Based Rejection sampling method is of order b, that is , while under the Naive method, the expected number of the iterations is , which is far more inefficient.


In general, exponential tilting, a parametric class of proposal distribution, solves the optimization problems conveniently, with its useful properties that directly characterize the distribution of the proposal. For this type of problem, to simulate conditionally on , among the class of simple distributions, the trick is to use NEFs, which helps to gain some control over the complexity and considerably speed up the computation. Indeed, there are deep mathematical reasons for using NEFs.

Drawbacks
Rejection sampling can lead to a lot of unwanted samples being taken if the function being sampled is highly concentrated in a certain region, for example a function that has a spike at some location. For many distributions, this problem can be solved using an adaptive extension (see adaptive rejection sampling). In addition, as the dimensions of the problem get larger, the ratio of the embedded volume to the "corners" of the embedding volume tends towards zero, thus a lot of rejections can take place before a useful sample is generated, thus making the algorithm inefficient and impractical. See curse of dimensionality. In high dimensions, it is necessary to use a different approach, typically a Markov chain Monte Carlo method such as Metropolis sampling or Gibbs sampling. (However, Gibbs sampling, which breaks down a multi-dimensional sampling problem into a series of low-dimensional samples, may use rejection sampling as one of its steps.)
Adaptive rejection sampling
For many distributions, finding a proposal distribution that includes the given distribution without a lot of wasted space is difficult. An extension of rejection sampling that can be used to overcome this difficulty and efficiently sample from a wide variety of distributions (provided that they have log-concave density functions, which is in fact the case for most of the common distributions—even those whose density functions are not concave themselves!) is known as adaptive rejection sampling (ARS).
There are three basic ideas to this technique as ultimately introduced by Gilks in 1992:[6]
- If it helps, define your envelope distribution in log space (e.g. log-probability or log-density) instead. That is, work with instead of directly.
- Often, distributions that have algebraically messy density functions have reasonably simpler log density functions (i.e. when is messy, may be easier to work with or, at least, closer to piecewise linear).
- Instead of a single uniform envelope density function, use a piecewise linear density function as your envelope instead.
- Each time you have to reject a sample, you can use the value of that you evaluated, to improve the piecewise approximation . This therefore reduces the chance that your next attempt will be rejected. Asymptotically, the probability of needing to reject your sample should converge to zero, and in practice, often very rapidly.
- As proposed, any time we choose a point that is rejected, we tighten the envelope with another line segment that is tangent to the curve at the point with the same x-coordinate as the chosen point.
- A piecewise linear model of the proposal log distribution results in a set of piecewise exponential distributions (i.e. segments of one or more exponential distributions, attached end to end). Exponential distributions are well behaved and well understood. The logarithm of an exponential distribution is a straight line, and hence this method essentially involves enclosing the logarithm of the density in a series of line segments. This is the source of the log-concave restriction: if a distribution is log-concave, then its logarithm is concave (shaped like an upside-down U), meaning that a line segment tangent to the curve will always pass over the curve.
- If not working in log space, a piecewise linear density function can also be sampled via triangle distributions [7]
- We can take even further advantage of the (log) concavity requirement, to potentially avoid the cost of evaluating when your sample is accepted.
- Just like we can construct a piecewise linear upper bound (the "envelope" function) using the values of that we had to evaluate in the current chain of rejections, we can also construct a piecewise linear lower bound (the "squeezing" function) using these values as well.
- Before evaluating (the potentially expensive) to see if your sample will be accepted, we may already know if it will be accepted by comparing against the (ideally cheaper) (or in this case) squeezing function that have available.
- This squeezing step is optional, even when suggested by Gilks. At best it saves you from only one extra evaluation of your (messy and/or expensive) target density. However, presumably for particularly expensive density functions (and assuming the rapid convergence of the rejection rate toward zero) this can make a sizable difference in ultimate runtime.







The method essentially involves successively determining an envelope of straight-line segments that approximates the logarithm better and better while still remaining above the curve, starting with a fixed number of segments (possibly just a single tangent line). Sampling from a truncated exponential random variable is straightfoward. Just take the log of a uniform random variable (with appropriate interva and corresponding truncation).
Unfortunately, ARS can only be applied from sampling from log-concave target densities. For this reason, several extensions of ARS have been proposed in literature for tackling non-log-concave target distributions.[8][9][10][11] Furthermore, different combinations of ARS and the Metropolis-Hastings method have been designed in order to obtain a universal sampler that builds a self-tuning proposal densities (i.e., a proposal automatically constructed and adapted to the target). This class of methods are often called as Adaptive Rejection Metropolis Sampling (ARMS) algorithms [12][13][14] (see some suitable Matlab code). The resulting adaptive techniques can be always applied but the generated samples are correlated in this case (although the correlation vanishes quickly to zero as the number of iterations grows).
See also
References
- ↑ Casella, George; Robert, Christian P.; Wells, Martin T. Generalized Accept-Reject sampling schemes. pp. 342–347. doi:10.1214/lnms/1196285403.
- ↑ Martino, Luca; Míguez, Joaquín (2010-11-01). "Generalized rejection sampling schemes and applications in signal processing". Signal Processing. 90 (11): 2981–2995. doi:10.1016/j.sigpro.2010.04.025.
- ↑ Neal, Radford M. (2003). "Slice Sampling". Annals of Statistics. 31 (3): 705–767. doi:10.1214/aos/1056562461. MR 1994729. Zbl 1051.65007.
- ↑ Bishop, Christopher (2006). "11.4: Slice sampling". Pattern Recognition and Machine Learning. Springer. ISBN 0-387-31073-8.
- ↑ Luengo, D.; Martino, L. "Efficient random variable generation: ratio of uniforms and polar rejection sampling". Electronics Letters. 48 (6). doi:10.1049/el.2012.0206.
- ↑ Adaptive Rejection Sampling for Gibbs Sampling. https://stat.duke.edu/~cnk/Links/tangent.method.pdf
- ↑ D.B. Thomas and W. Luk , Non-uniform random number generation through piecewise linear approximations, 2006. http://www.doc.ic.ac.uk/~wl/papers/iee07dt.pdf
- ↑ Hörmann, Wolfgang (1995-06-01). "A Rejection Technique for Sampling from T-concave Distributions". ACM Trans. Math. Softw. 21 (2): 182–193. doi:10.1145/203082.203089. ISSN 0098-3500.
- ↑ Evans, M.; Swartz, T. (1998-12-01). "Random Variable Generation Using Concavity Properties of Transformed Densities". Journal of Computational and Graphical Statistics. 7 (4): 514–528. doi:10.2307/1390680. JSTOR 1390680.
- ↑ Martino, Luca; Míguez, Joaquín (2010-08-25). "A generalization of the adaptive rejection sampling algorithm". Statistics and Computing. 21 (4): 633–647. doi:10.1007/s11222-010-9197-9. ISSN 0960-3174.
- ↑ Görür, Dilan; Teh, Yee Whye (2011-01-01). "Concave-Convex Adaptive Rejection Sampling". Journal of Computational and Graphical Statistics. 20 (3): 670–691. doi:10.1198/jcgs.2011.09058. ISSN 1061-8600.
- ↑ Gilks, W. R.; Best, N. G.; Tan, K. K. C. (1995-01-01). "Adaptive Rejection Metropolis Sampling within Gibbs Sampling". Journal of the Royal Statistical Society. Series C (Applied Statistics). 44 (4): 455–472. doi:10.2307/2986138. JSTOR 2986138.
- ↑ Meyer, Renate; Cai, Bo; Perron, François (2008-03-15). "Adaptive rejection Metropolis sampling using Lagrange interpolation polynomials of degree 2". Computational Statistics & Data Analysis. 52 (7): 3408–3423. doi:10.1016/j.csda.2008.01.005.
- ↑ Martino, L.; Read, J.; Luengo, D. (2015-06-01). "Independent Doubly Adaptive Rejection Metropolis Sampling Within Gibbs Sampling". IEEE Transactions on Signal Processing. 63 (12): 3123–3138. doi:10.1109/TSP.2015.2420537. ISSN 1053-587X.
- Robert, C.P. and Casella, G. "Monte Carlo Statistical Methods" (second edition). New York: Springer-Verlag, 2004.
- J. von Neumann, "Various techniques used in connection with random digits. Monte Carlo methods", Nat. Bureau Standards, 12 (1951), pp. 36–38.