Phonetic transcription
Phonetic transcription (also known as phonetic script or phonetic notation) is the visual representation of speech sounds (or phones). The most common type of phonetic transcription uses a phonetic alphabet, such as the International Phonetic Alphabet.
Phonetic transcription versus orthography
The pronunciation of words in many languages, as distinct from their written form (orthography), has undergone significant change over time. Pronunciation can also vary greatly among dialects of a language. Standard orthography in some languages, particularly French, English, and Irish, is often irregular, and makes it difficult to predict pronunciation from spelling. For example, the words bough and through do not rhyme in English, even though their spellings might suggest they do. In French, the sequence "-ent" is pronounced /ɑ̃/ in accent, but is silent in "posent".
Other languages, such as Spanish and Italian have a more consistent—though still imperfect—relationship between orthography and pronunciation (phonemic orthography).
Therefore, phonetic transcription can provide a function that orthography cannot. It displays a one-to-one relationship between symbols and sounds, unlike traditional writing systems. Phonetic transcription allows us to step outside orthography and examine differences in pronunciation between dialects within a given language, as well as to identify changes in pronunciation that may take place over time.
Narrow versus broad transcription
Phonetic transcription may aim to transcribe the phonology of a language, or it may be used to go further and specify the precise phonetic realisation. In all systems of transcription we may therefore distinguish between broad transcription and narrow transcription. Broad transcription indicates only the most noticeable phonetic features of an utterance, whereas narrow transcription encodes more information about the phonetic variations of the specific allophones in the utterance. The difference between broad and narrow is a continuum. One particular form of a broad transcription is a phonemic transcription, which disregards all allophonic difference, and, as the name implies, is not really a phonetic transcription at all, but a representation of phonemic structure.
For example, one particular pronunciation of the English word little may be transcribed using the IPA as /ˈlɪtəl/ or [ˈlɪɾɫ̩]; the broad, phonemic transcription, placed between slashes, indicates merely that the word ends with phoneme /l/, but the narrow, allophonic transcription, placed between square brackets, indicates that this final /l/ ([ɫ]) is dark (velarized).
The advantage of the narrow transcription is that it can help learners to get exactly the right sound, and allows linguists to make detailed analyses of language variation. The disadvantage is that a narrow transcription is rarely representative of all speakers of a language. Most Americans and Australians would pronounce the /t/ of little as a tap [ɾ]. Some people in southern England would say /t/ as [ʔ] (a glottal stop) and/or the second /l/ as [w] or something similar. A further disadvantage in less technical contexts is that narrow transcription involves a larger number of symbols that may be unfamiliar to non-specialists.
The advantage of the broad transcription is that it usually allows statements to be made which apply across a more diverse language community. It is thus more appropriate for the pronunciation data in foreign language dictionaries, which may discuss phonetic details in the preface but rarely give them for each entry. A rule of thumb in many linguistics contexts is therefore to use a narrow transcription when it is necessary for the point being made, but a broad transcription whenever possible.
Types of notational systems
Most phonetic transcription is based on the assumption that linguistic sounds are segmentable into discrete units that can be represented by symbols.
Alphabetic
.pdf.jpg)
The International Phonetic Alphabet (IPA) is one of the most popular and well-known phonetic alphabets. It was originally created by primarily British language teachers, with later efforts from European phoneticians and linguists. It has changed from its earlier intention as a tool of foreign language pedagogy to a practical alphabet of linguists. It is currently becoming the most often seen alphabet in the field of phonetics.
Most American dictionaries for native English-speakers—American Heritage Dictionary of the English Language, Random House Dictionary of the English Language, Webster's Third New International Dictionary—employ respelling systems based on the English alphabet, with diacritical marks over the vowels and stress marks.[1] (See Wikipedia:United States dictionary transcription for a generic version.)
Another commonly encountered alphabetic tradition was originally created for the transcription of Native American and European languages, and is still commonly used by linguists of Slavic, Indic, Uralic, Semitic, and Caucasian languages. This is sometimes labeled the Americanist phonetic alphabet, but this is misleading because it has always been widely used for languages outside the Americas. The difference between these alphabets and IPA is small, although often the specially created characters of the IPA are abandoned in favour of already existing characters with diacritics (e.g. many characters are borrowed from Eastern European orthographies) or digraphs.
There are also extended versions of the IPA, for example: Ext-IPA, VoQS, and Luciano Canepari's canIPA.
Aspects of alphabetic transcription
Other alphabets, such as Hangul, may have their own phonetic extensions. There also exist featural phonetic transcription systems, such as Alexander Melville Bell's Visible Speech and its derivatives.
The International Phonetic Association recommends that a phonetic transcription should be enclosed in square brackets "[ ]". A transcription that specifically denotes only phonological contrasts may be enclosed in slashes "/ /" instead. If one is in doubt, it is best to use brackets, for by setting off a transcription with slashes one makes a theoretical claim that every symbol within is phonemically contrastive for the language being transcribed.
Phonetic transcriptions try to objectively capture the actual pronunciation of a word, whereas phonemic transcriptions are model-dependent. For example, in The Sound Pattern of English, Noam Chomsky and Morris Halle transcribed the English word night phonemically as /nixt/. In this model, the phoneme /x/ is never realized as [x], but shows its presence by "lengthening" the preceding vowel. The preceding vowel in this case is the phoneme /i/, which is pronounced [aɪ] when "long". So phonemic /nixt/ is equivalent to phonetic [naɪt], but underlying this analysis is the belief that historical sounds such as the gh in night may remain in a word long after they have ceased to be pronounced, or that a phoneme may exist in a language without ever being directly expressed. (This was later rejected by both Chomsky and Halle.)
For phonetic transcriptions, there is flexibility in how closely sounds may be transcribed. A transcription that gives only a basic idea of the sounds of a language in the broadest terms is called a broad transcription; in some cases this may be equivalent to a phonemic transcription (only without any theoretical claims). A close transcription, indicating precise details of the sounds, is called a narrow transcription. These are not binary choices, but the ends of a continuum, with many possibilities in between. All are enclosed in brackets.
For example, in some dialects the English word pretzel in a narrow transcription would be [ˈpɹ̥ʷɛʔts.ɫ̩], which notes several phonetic features that may not be evident even to a native speaker. An example of a broad transcription is [ˈpɹ̥ɛts.ɫ̩], which only indicates some of the easier to hear features. A yet broader transcription would be [ˈpɹɛts.l]. Here every symbol represents an unambiguous speech sound, but without going into any unnecessary detail. None of these transcriptions make any claims about the phonemic status of the sounds. Instead, they represent certain ways in which it is possible to produce the sounds that make up the word.
There are also several possibilities in how to transcribe this word phonemically, but here the differences are generally not of precision, but of analysis. For example, pretzel could be /ˈprɛts.l̩/ or /ˈprets.əl/. The special symbol for English r is not used, for it is not meaningful to distinguish it from a rolled r. The second transcription claims that there are two vowels in the word, even if they can't both be heard, while the first claims there is only one.
However, phonemic transcriptions may also be broad or narrow, or perhaps it would be better to say abstract versus concrete. They may show a fair amount of phonetic detail, usually of a phoneme's most common allophone, but because they are abstract symbols they do not need to resemble any sound at all directly. Phonemic symbols will frequently be chosen to avoid diacritics as much as possible, under a 'one sound one symbol' policy, or may even be restricted to the ASCII symbols of a typical keyboard. For example, the English word church may be transcribed as /tʃɝːtʃ/, a close approximation of its actual pronunciation, or more abstractly as /crc/, which is easier to type. Phonemic symbols should always be explained, especially when they are as divergent from actual pronunciation as /crc/.
Occasionally a transcription will be enclosed in pipes ("| |"). This goes beyond phonology into morphological analysis. For example, the words pets and beds could be transcribed phonetically as [pʰɛʔts] and [b̥ɛd̥z̥] (in a fairly narrow transcription), and phonemically as /pets/ and /bedz/. Because /s/ and /z/ are separate phonemes in English, they receive separate symbols in the phonemic analysis. However, you probably recognize that underneath this, they represent the same plural ending. This can be indicated with the pipe notation. If you believe the plural ending is essentially an s, as English spelling would suggest, the words can be transcribed |pets| and |beds|. If, as most linguists would probably suggest, it is essentially a z, these would be |petz| and |bedz|.
To avoid confusion with IPA symbols, it may be desirable to specify when native orthography is being used, so that, for example, the English word jet is not read as "yet". This is done with angle brackets or chevrons: ⟨jet⟩. It is also common to italicize such words, but the chevrons indicate specifically that they are in the original language's orthography, and not in English transliteration.
Iconic
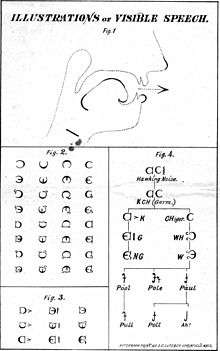
In iconic phonetic notation, the shapes of the phonetic characters are designed so that they visually represent the position of articulators in the vocal tract. This is unlike alphabetic notation, where the correspondence between character shape and articulator position is arbitrary. This notation is potentially more flexible than alphabetic notation in showing more shades of pronunciation (MacMahon 1996:838–841). An example of iconic phonetic notation is the Visible Speech system, created by Scottish phonetician Alexander Melville Bell (Ellis 1869:15).
Analphabetic
Another type of phonetic notation that is more precise than alphabetic notation is analphabetic phonetic notation. Instead of both the alphabetic and iconic notational types' general principle of using one symbol per sound, analphabetic notation uses long sequences of symbols to precisely describe the component features of an articulatory gesture (MacMahon 1996:842–844). This type of notation is reminiscent of the notation used in chemical formulas to denote the composition of chemical compounds. Although more descriptive than alphabetic notation, analphabetic notation is less practical for many purposes (e.g. for descriptive linguists doing fieldwork or for speech pathologists impressionistically transcribing speech disorders). As a result, this type of notation is uncommon.
Two examples of this type were developed by the Danish Otto Jespersen (1889) and American Kenneth Pike (1943). Pike's system, which is part of a larger goal of scientific description of phonetics, is particularly interesting in its challenge against the descriptive method of the phoneticians who created alphabetic systems like the IPA. An example of Pike's system can be demonstrated by the following. A syllabic voiced alveolar nasal consonant (/n̩/ in IPA) is notated as
- MaIlDeCVoeIpvnnAPpaatdtltnransnsfSpvavdtlvtnransssfTpgagdtlwvtitvransnsfSrpFSs
In Pike's notation there are 5 main components (which are indicated using the example above):
- M - manner of production (i.e., MaIlDe)
- C - manner of controlling (i.e., CVoeIpvnn)
- description of stricture (i.e., APpaatdtltnransnsfSpvavdtlvtnransssfTpgagdtlwvtitvransnsf)
- S - segment type (i.e., Srp)
- F - phonetic function (i.e., FSs)
The components of the notational hierarchy of this consonant are explained below:
|
|
|
Bibliography
- Albright, Robert W. (1958). The International Phonetic Alphabet: Its Background and Development. International Journal of American Linguistics (Vol. 24, No. 1, Part 3); Indiana University Research Center in Anthropology, Folklore, and Linguistics, publ. 7. Baltimore. (Doctoral dissertation, Stanford University, 1953).
- Canepari, Luciano. (2005). A Handbook of Phonetics: ⟨Natural⟩ Phonetics. München: Lincom Europa, pp. 518. ISBN 3-89586-480-3 (hb).
- Ellis, Alexander J. (1869–1889). On Early English Pronunciation (Parts 1 & 5). London: Philological Society by Asher & Co.; London: Trübner & Co.
- International Phonetic Association. (1949). The Principles of the International Phonetic Association, Being a Description of the International Phonetic Alphabet and the Manner of Using It, Illustrated by Texts in 51 Languages. London: University College, Department of Phonetics.
- International Phonetic Association. (1999). Handbook of the International Phonetic Association: A Guide to the Use of the International Phonetic Alphabet. Cambridge: Cambridge University Press. ISBN 0-521-65236-7 (hb); ISBN 0-521-63751-1 (pb).
- Jespersen, Otto. (1889). The Articulations of Speech Sounds Represented by Means of Analphabetic Symbols. Marburg: Elwert.
- Kelly, John. (1981). The 1847 Alphabet: An Episode of Phonotypy. In R. E. Asher & E. J. A. Henderson (Eds.), Towards a History of Phonetics. Edinburgh: Edinburgh University Press.
- Kemp, J. Alan. (1994). Phonetic Transcription: History. In R. E. Asher & J. M. Y. Simpson (Eds.), The Encyclopedia of Language and Linguistics (Vol. 6, pp. 3040–3051). Oxford: Pergamon.
- MacMahon, Michael K. C. (1996). Phonetic Notation. In P. T. Daniels & W. Bright (Ed.), The World's Writing Systems (pp. 821–846). New York: Oxford University Press. ISBN 0-19-507993-0.
- Pike, Kenneth L. (1943). Phonetics: A Critical Analysis of Phonetic Theory and a Technique for the Practical Description of Sounds. Ann Arbor: University of Michigan Press.
- Pullum, Geoffrey K.; & Ladusaw, William A. (1986). Phonetic Symbol Guide. Chicago: University of Chicago Press. ISBN 0-226-68532-2.
- Sweet, Henry. (1880–1881). Sound Notation. Transactions of the Philological Society, 177-235.
- Sweet, Henry. (1971). The Indispensable Foundation: A Selection from the Writings of Henry Sweet. Henderson, Eugénie J. A. (Ed.). Language and Language Learning 28. London: Oxford University Press.
See also
- Pronunciation respelling for English
- Phonetics
- Pronunciation spelling
- Phonetic spelling
- Transliteration
- Eye dialect
- Romanization
- English Phonetic Alphabet
- Orthographic transcription
Notational systems
- Americanist phonetic notation
- International Phonetic Alphabet
- Stokoe notation to represent sign languages,
- Uralic Phonetic Alphabet (UPA)
- Visible Speech
- Teuthonista
References
- ↑ Landau, Sidney (2001) Dictionaries: The Art and Craft of Lexicography, 2nd ed., p 118. Cambridge University Press. ISBN 0-521-78512-X.
External links
- Official home page of the IPA
- canIPA Natural Phonetics : Luciano Canepari's extended version of IPA (500 basic, 300 complementary, and 200 supplementary symbols), with a lot of downloadable PDF's
- Phonetic Transcription of English
- PhoTransEdit - English Phonetic Transcription Editor : PhoTransEdit is a free tool created to make typing phonetic transcriptions easier. It includes automatic phonemic transcription (in RP and General American) of English texts and a phonetic keyboard to edit them. The transcription can be pasted into other editors (e.g. Microsoft Word) or exported to use it in HTML pages.
- IPANow! - Automatic Foreign Language IPA Transcription : IPANow! is shareware that automatically creates phonetic transcriptions of texts in Latin, Italian, German, and French.